Study notes
Types of data
- Structured
table-based source systems such as a relational database or from a flat file such as a comma separated (CSV) file
The primary element of a structured file is that the rows and columns are aligned consistently throughout the file. - Semi-structured
data such as JavaScript object notation (JSON) files, which may require flattening prior to loading into your source system.
When flattened, this data doesn't have to fit neatly into a table structure. - Unstructured
data stored as key-value pairs that don't adhere to standard relational models and Other types of unstructured data that are commonly used include portable data format (PDF), word processor documents, and images.
- Operational data
Usually transactional data that is generated and stored by applications, often in a relational or non-relational database. - Analytical data
Data that has been optimized for analysis and reporting, often in a data warehouse. - Streaming data
Perpetual sources of data that generate data values in real-time, often relating to specific events.
Common sources of streaming data include internet-of-things (IoT) devices and social media feeds. - Data pipelines
Used to orchestrate activities that transfer and transform data.
Pipelines are the primary way in which data engineers implement repeatable extract, transform, and load (ETL) solutions that can be triggered based on a schedule or in response to events. - Data lakes
Storage repository that holds large amounts of data in native, raw formats
Data lake stores are optimized for scaling to massive volumes (terabytes or petabytes) of data. - Data warehouses
Centralized repository of integrated data from one or more disparate sources.
Data warehouses store current and historical data in relational tables that are organized into a schema that optimizes performance for analytical queries. - Apache Spark
Parallel processing framework that takes advantage of in-memory processing and a distributed file storage. It's a common open-source software (OSS) tool for big data scenarios.
- Data integration
Establishing links between operational and analytical services and data sources to enable secure, reliable access to data across multiple systems. - Data transformation
Operational data usually needs to be transformed into suitable structure and format for analysis
It is often as part of an extract, transform, and load (ETL) process; though increasingly a variation in which you extract, load, and transform (ELT) the data is used to quickly ingest the data into a data lake and then apply "big data" processing techniques to transform it. Regardless of the approach used, the data is prepared to support downstream analytical needs. - Data consolidation
Combining data that has been extracted from multiple data sources into a consistent structure - usually to support analytics and reporting.
Commonly, data from operational systems is extracted, transformed, and loaded into analytical stores such as a data lake or data warehouse.
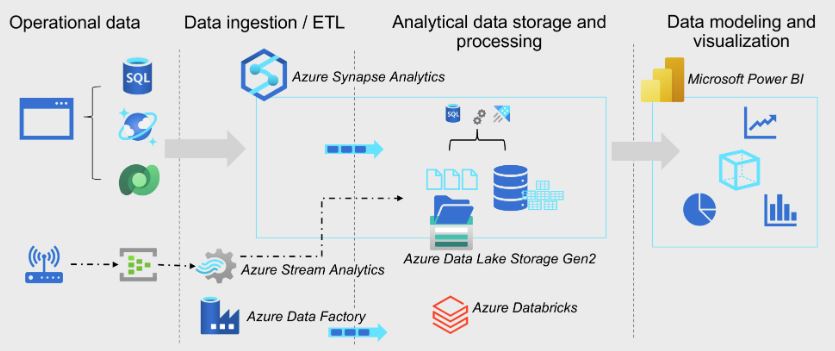
- Operational data is generated by applications and devices and..
- Stored in Azure data storage services such as Azure SQL Database, Azure Cosmos DB, and Microsoft Dataverse.
- Streaming data is captured in event broker services such as Azure Event Hubs.
- Operational data must be captured, ingested, and consolidated into analytical store and ...
- From where it can be modeled and visualized in reports and dashboards.
The core Azure technologies used to implement data engineering workloadsinclude:
- Azure Synapse Analytics
Azure Synapse Analyticsincludes functionality for pipelines, data lakes, and relational data warehouses. - Azure Data Lake Storage Gen2
- Azure Stream Analytics
- Azure Data Factory
- Azure Databricks
Azure Data Lake Storage Gen2
Provides a cloud-based solution for data lake storage in Microsoft Azure, and underpins many large-scale analytics solutions built on Azure.
A data lake is a repository of data that is stored in its natural format, usually as blobs or files. Azure Data Lake Storage is a comprehensive, massively scalable, secure, and cost-effective data lake solution for high performance analytics built into Azure.
- Hadoop compatible access.
You can store the data in one place and access it through compute technologies including Azure Databricks, Azure HDInsight, and Azure Synapse Analytics - Security
Data Lake Storage supports access control lists (ACLs) and Portable Operating System Interface (POSIX) permissions that don't inherit the permissions of the parent directory - Performance
- Data redundancy
- Blob
in terms of blob manageability the blobs are stored as a single-level hierarchy in a flat namespace.
Flat namespaces, by contrast, require several operations proportionate to the number of objects in the structure. - Azure Data Lake Storage Gen2
builds on blob storage and optimizes I/O of high-volume data by using a hierarchical namespace that organizes blob data into directories, and stores metadata about each directory and the files within it.
Hierarchical namespaces keep the data organized, which yields better storage and retrieval performance for an analytical use case and lowers the cost of analysis.
- Ingest
The ingestion phase identifies the technology and processes that are used to acquire the source data. This data can come from files, logs, and other types of unstructured data that must be put into the data lake.
The technology that is used will vary depending on the frequency that the data is transferred.- Batch movement of data, pipelines in Azure Synapse Analytics or Azure Data Factory
- Real-time ingestion of data, Apache Kafka for HDInsight or Stream Analytics .
- Store
The store phase identifies where the ingested data should be placed. Azure Data Lake Storage Gen2 provides a secure and scalable storage solution that is compatible with commonly used big data processing technologies. - Prep and train
The prep and train phase identifies the technologies that are used to perform data preparation and model training and scoring for machine learning solutions.
Common technologies that are used in this phase are Azure Synapse Analytics, Azure Databricks, Azure HDInsight, and Azure Machine Learning. - Model and serve
Involves the technologies that will present the data to users. These technologies can include visualization tools such as Microsoft Power BI, or analytical data stores such as Azure Synapse Analytics. Often, a combination of multiple technologies will be used depending on the business requirements.
- Big data processing and analytics
Usually refer to analytical workloads that involve massive volumes of data in a variety of formats that needs to be processed at a fast velocity - the so-called "three v's".
Big data services such as Azure Synapse Analytics, Azure Databricks, and Azure HDInsight can apply data processing frameworks such as Apache Spark, Hive, and Hadoop. - Data warehousing
Integrate large volumes of data stored as files in a data lake with relational tables in a data warehouse.
There are multiple ways to implement this kind of data warehousing architecture. The diagram shows a solution in whichAzure Synapse Analytics hosts pipelines to perform extract, transform, and load (ETL) processes using Azure Data Factory technology. - Real-time data analytics
streaming data requires a solution that can capture and process a boundless stream of data events as they occur.
Streaming events are often captured in a queue for processing. There are multiple technologies you can use to perform this task, including Azure Event Hubs as shown in the image.
Azure Stream Analytics enables you to create jobs that query and aggregate event data as it arrives, and write the results in an output sink - Data science and machine learning
Involves the statistical analysis of large volumes of data, often using tools such as Apache Spark and scripting languages such as Python. Azure Data Lake Storage Gen 2 provides a highly scalable cloud-based data store for the volumes of data required in data science workloads.
Analytical technique that organizations commonly use:
- Descriptive analytics
which answers the question “What is happening in my business?”. The data to answer this question is typically answered through the creation of a data warehouse in which historical data is persisted in relational tables for multidimensional modeling and reporting. - Diagnostic analytics,
which deals with answering the question “Why is it happening?”. This may involve exploring information that already exists in a data warehouse, but typically involves a wider search of your data estate to find more data to support this type of analysis. - Predictive analytics,
which enables you to answer the question “What is likely to happen in the future based on previous trends and patterns?” - Prescriptive analytics,
which enables autonomous decision making based on real-time or near real-time analysis of data, using predictive analytics.
To support the analytics needs of today's organizations, Azure Synapse Analytics combines a centralized service for data storage and processing with an extensible architecture through which linked services enable you to integrate commonly used data stores, processing platforms, and visualization tools.
A Synapse Analytics workspace defines an instance of the Synapse Analytics service in which you can manage the services and data resources needed for your analytics solution.
A workspace typically has a default data lake, which isimplemented as a linked serviceto an Azure Data Lake Storage Gen2 container.
Azure Synapse Analytics includes built-in support for creating, running, and managing pipelines that orchestrate the activities necessary
- to retrieve data from a range of sources,
- transform the data as required, and
- load the resulting transformed data into an analytical store.
- A built-in serverless pool that is optimized for using relational SQL semantics to query file-based data in a data lake.
use the built-in serverless pool for cost-effective analysis and processing of file data in the data lake - Customdedicated SQL pools that host relational data warehouses.
use dedicated SQL pools to create relational data warehouses for enterprise data modeling and reporting.
In Azure Synapse Analytics, you can create one or more Spark pools and use interactive notebooks to combine code and notes as you build solutions for data analytics, machine learning, and data visualization.
Exploring data with Data Explorer
Data Explorer uses an intuitive query syntax named Kusto Query Language (KQL) to enable high performance, low-latency analysis of batch and streaming data.
Azure Synapse Analytics can be integrated with other Azure data services for end-to-end analytics solutions. Integrated solutions include:
- Azure Synapse Link
enables near-realtime synchronization between operational data in Azure Cosmos DB, Azure SQL Database, SQL Server, and Microsoft Power Platform Dataverse and analytical data storage that can be queried in Azure Synapse Analytics. - Microsoft Power BI integration
enables data analysts to integrate a Power BI workspace into a Synapse workspace, and perform interactive data visualization in Azure Synapse Studio. - Microsoft Purview integration
enables organizations to catalog data assets in Azure Synapse Analytics, and makes it easier for data engineers to find data assets and track data lineage when implementing data pipelines that ingest data into Azure Synapse Analytics. - Azure Machine Learning integration
enables data analysts and data scientists to integrate predictive model training and consumption into analytical solutions.
- Large-scale data warehousing
Data warehousing includes the need to integrate all data, including big data, to reason over data for analytics and reporting purposes from a descriptive analytics perspective, independent of its location or structure. - Advanced analytics
Enables organizations to perform predictive analytics using both the native features of Azure Synapse Analytics, and integrating with other technologies such as Azure Machine Learning. - Data exploration and discovery
The serverless SQL pool functionality provided by Azure Synapse Analytics enables Data Analysts, Data Engineers and Data Scientist alike to explore the data within your data estate. This capability supports data discovery, diagnostic analytics, and exploratory data analysis. - Real time analytics
Azure Synapse Analytics can capture, store and analyze data in real-time or near-real time with features such as Azure Synapse Link, or through the integration of services such as Azure Stream Analytics and Azure Data Explorer. - Data integration
Azure Synapse Pipelines enables you to ingest, prepare, model and serve the data to be used by downstream systems. This can be used by components of Azure Synapse Analytics exclusively. - Integrated analytics
With the variety of analytics that can be performed on the data at your disposal, putting together the services in a cohesive solution can be a complex operation. Azure Synapse Analytics removes this complexity by integrating the analytics landscape into one service. That way you can spend more time working with the data to bring business benefit, than spending much of your time provisioning and maintaining multiple systems to achieve the same outcomes.
Terms, Login to view
Hands-On Explore Azure Synapse Analytics, Login to view